
반응형
시작하기 전에
핑계입니다.
사실 군복학을 사유로 10월달 초 부터 수업에 참여하게 되어서 거의 독학으로 공부하고 과제를 진행한 것 같다.
그렇기에 부족하고 잘못된 내용이 적지 않을것 같은데,, 많은 피드백 부탁드립니다.
내가 생각하는 강화학습이란
- 환경을 input으로 받고 task와 환경에 맞는 행동 정책을 학습한 에이전트를 output으로 반환하는 구조라고 생각한다.
- 이런 환경에 맞는 행동을 학습하는 과정은 보상이 중요하다, 결국 에이전트는 보상을 통해서 환경을 학습하는 것이다.
- 즉 강화학습을 설계하는 과정은 환경과 task에 맞는 행동 정책(가치 함수), 보상을 설계하는 과정이라고 생각했다.
중간고사 과제(미로찾기, 그리고 3가지의 열쇠와 문을 곁들인)
환경 설명
https://docs.google.com/document/d/11gPfnmHj1430d15T5cIFbpdtQmMyzKy7N0WXPyc12mE/edit?usp=sharing
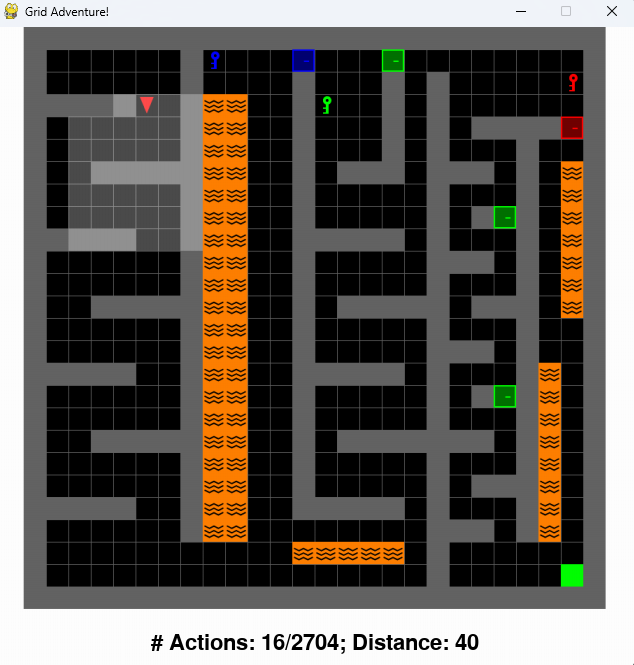
- task: 최단 거리로 미로를 탈출
- action
- ACTION_LEFT
- ACTION_RIGHT
- ACTION_FORWARD
- ACTION_PICKUP
- ACTION_DROP
- ACTION_UNLOCK
- 환경, 행동, 과제에 대한 설명
- 용암과, 행동이 2704를 초과하면 게임 오버다
- 에이전트는 왼쪽으로 90도 회전, 오른쪽으로 90도 회전, 전진을 사용하면 이동할 수 있다.
- 에이전트는 한번에 하나의 열쇠만 소지할 수 있다.
- 문은 같은 색상의 열쇠를 소지하고 있다면 pickup을 통해서 열 수 있으며 열쇠는 소모되지 않는다.
- 외부 라이브러리나 다른 사람들의 구현물을 사용하지 않고 모두 직접 작업하여 학습시킬 것
- 환경 정보는 매 행동마다 제공된다.
학습 설계 개요
- 보상
- 에이전트가 최적경로로 이동할 수록 큰 보상을 받도록 함
- bfs 알고리즘을 통해서 최적경로를 찾고 해당 셀을 이동하면 보상을 받도록 함
- bfs 알고리즘을 통해서 모든셀과 목적지와의 거리를 측정하고 거리가 가까울수록 좋기 때문에 역수 처리와, 0~1 정규화를 해주었다.
- 위 두 개의 테이블 보상 정보를 결합해주었다.
- 또한 같은 셀을 반복하지 않도록 한 번 보상을 받은 셀을 -10%로 값을 줄여나갔다.
- 열쇠를 획득, 문을 열기, 문을 지남에 따라 색깔 별로 한번 씩 보상을 주도록 했다.
- 목표 보상의 경우는 목적지의 도달했을 경우의 행동이 적을 수록 높은 보상을 받을 수 있도록 했다.
- 또한 최적의 경로로 수렴할 수 있도록 하기 위해서 행동 한 번마다 -1씩 누적되도록 설정 해주었다.
- 용암과 벽을 향해 포워드하는 경우 패널티 보상을 주도록 설정해주었다.
- 보상을 설계하는 과정에서 제일 중요한 것은 최적의 경로와 행동으로 수행했을 경우가 어떠한 루트보다 보상이 크도록 설계해야 한다는 것이다.
- 에이전트가 최적경로로 이동할 수록 큰 보상을 받도록 함
- q_learning
- q_table의 구성
- 에이전트의 위치 : (x,y)
- 에이전트의 방향 : (0~3)
- 에이전트가 현재 소지하고 있는 열쇠 타입 : (0~4)
- 초록문의 현재 상태: 0~2
- 파란문의 현재 상태: 0~2
- 빨간문의 현재 상태: 0~2
- 행동 0~5
- 사실 초록문이 3개라 최적경로에 속해 있는 초록문만 고려하도록 해서 코드가 완전하지 않았다. 차라리 넣어주고 내부적으로 수정해줬다면 더 긍정적이였을 것 같다.
- 학습 정책(가치 함수)
- alpha : 학습률, 0.1을 사용하다 값이 최적에 가까워진다면 학습률을 낮추었다
- gamma: 할인률, 0.95 현재 보상만을 계산하는게 아닌 다음 행동에 대한 보상에 대한 할인률, 즉 반영 비율에 대한 조정으로 0.95를 계속 사용했다.
- q_table의 구성

학습 과정
- 코드 자체는 앱실론이 선형적으로 감소되도록 설정했지만 중간에 못참고 학습이 되는거 같으면 중간에 멈추고 조절해줘서 결과적으로는 다음과 같은 앱실론으로 학습했다.
- $\epsilon = 0.5$ → 4000 에피소드
- $\epsilon = 0.3$ → 2000 에피소드
- $\epsilon = 0.1$ → 4000 에피소드
- $\epsilon = 0.05$ → 1000 에피소드
- $\epsilon = 0.01$ → 1000 + $\alpha$ 에피소드
최종 결과와 후기
- 결과적으로 주어진 task에서 가장 적은 행동 경로를 학습 할 수 있었다.
- 그래도 강화학습을 처음으로 구현해 보면서 맨날 이론만, 즉 수도 코드로만 보던 내용을 직접 구현해보니 확실히 느낌이 달랐고 보상 구현이 까다롭기도 하지만 주어진 task에 맞는 학습법과 올바른(구조적 문제가 없는)코드를 작성을 중요성을 느꼈다.
- 중간고사 과제이기에 최적경로를 달성했기 때문에 1등을 했다. 하지만 공동 1등을 한 팀은 같은 q_learning을 사용했지만 추가적으로 ucb 알고리즘을 사용해서 5분만에 최적경로를 학습한다는 것을 보면 주어진 task에 대한 이해가 부족했고 그것에 대해서 중요하게 생각하지 않은 부분에 반성을 하게 되었다.
- 문제 환경이 26x26이고 매 행동에 대한 현재 환경 정보를 받을 수 있기 때문에 모든 행동에 대한 보상을 계산하는 ucb 알고리즘이 효과적이였다고 생각한다.
- 문제 환경이 26x26이고 매 행동에 대한 현재 환경 정보를 받을 수 있기 때문에 모든 행동에 대한 보상을 계산하는 ucb 알고리즘이 효과적이였다고 생각한다.
- q leaning에 대해서 깨달은 점
- 처음에는 q_leaning에 대한 이해도가 떨어져서 환경 grid 정보와 현재 에이전트의 방향만 값을 주면서 시간을 버렸다.
- 결과적으로 깨달은 부분은 에이전트가 환경을 학습할 때는 동일한 환경 정보에 대한 같은 최적의 행동 도출하는 것이 학습을 잘한것이라 말할 수 있다.
- 그렇기 에이전트 입장에서 문 상태와 열쇠 상태와 같은 환경이 변화되는 부분에 대한 정보를 주어주지 않다면 에이전트는 죽을때 까지 학습할 수 없을 것이다.
- 한줄로 정리하자면 학습이란 현재 환경에 대한 최적의 행동을 도출하는 것이기에, 적어도 q learning에서는 에이전트에게 제공하는 환경에 대한 정보가 미흡하다면 최적의 행동을 학습하기 어렵다.
- 다음 과제는 딥러닝을 활용한 DQN을 사용할 것이다!
- https://github.com/hojuna/knu_reinforcement_learning
반응형
'ai' 카테고리의 다른 글
| qwk metrics (0) | 2024.05.09 |
|---|---|
| optimizer & adam (0) | 2024.05.08 |
| 분류 평가 지표 (0) | 2024.03.18 |